

该系列课程我们将跟随libfuzzer-workshop来学习libfuzz这个fuzz框架。该系列一共有12课,其列表如下:
1.介绍fuzz测试
2.传统Fuzz技术案例
3.代码覆盖率fuzz
4.写fuzzers
5.发现Heartbleed漏洞 (CVE-2014-0160)
6.发现c-ares漏洞(CVE-2016-5180)
7.如何提高fuzzer效率
8.fuzz libxml2,学习如何提高fuzzer和分析性能
9.fuzz libpng,学习语料库种子的重要性
10.fuzz re2
11.fuzz pcre2
12.与chrome整合,家庭作业
前置知识
在项目中,我们会用到LLVM和Clang来编译程序,下面将分别介绍LLVM和Clang。
编译流程
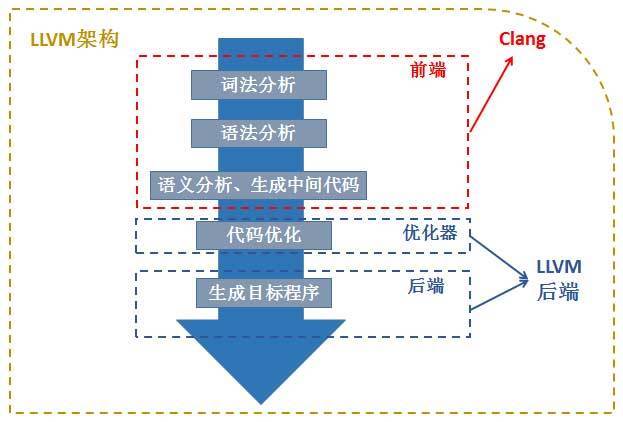
传统编译器基本分为三段式,前端、优化器和后端。
前端负责解析源代码,检查语法错误,并将其翻译为抽象的语法树;
优化器对这一中间代码进行优化,试图使代码更高效;
后端则负责将优化器优化后的中间代码转换为目标机器的代码,这一过程后端会最大化的利用目标机器的特殊指令,以提高代码的性能。
而我们将用到的LLVM和Clang则在编译过程中充当了前端,优化器,后端这三个责任。
llvm
LLVM是一个模块化和可重用的编译器和工具链技术的集合。简单来说提供了编译过程一整套,包括前端,优化器,后端一整套流程的工具库,而又由于其高度的扩展性,可以
clang
clang则是llvm下的一个子项目,是一个 C、C++、Objective-C 和 Objective-C++ 编程语言的编译器前端,采用底层虚拟机(LLVM)作为后端。
LLVM和Clang的关系
下图是LLVM和Clang组合编译的一种方式,可以从这种编译方式了解到LLVM和Clang的关系,既Clang作为前端,LLVM作为优化器和后端。
环境搭建
1.下载ubuntu
http://releases.ubuntu.com/16.04/ubuntu-16.04.7-desktop-amd64.iso
安装ubuntu,把CD和软盘切换成自动检测。
即可在VM选项中选择安装VMWARE TOOL。当选择安装VMWARE TOOL后会在虚拟机的CD显示栏中弹出vmwaretool的磁盘光驱。解压CD中的vmwaretool到任意文件夹,运行 sudo ./vmware-install.pl,输入yes,一直回车,重启即可安装完成。
2.切换成国内源
sudo gedit /etc/apt/sources.list
deb http://mirrors.aliyun.com/ubuntu/ xenial main
deb-src http://mirrors.aliyun.com/ubuntu/ xenial main
deb http://mirrors.aliyun.com/ubuntu/ xenial-updates main
deb-src http://mirrors.aliyun.com/ubuntu/ xenial-updates main
deb http://mirrors.aliyun.com/ubuntu/ xenial universe
deb-src http://mirrors.aliyun.com/ubuntu/ xenial universe
deb http://mirrors.aliyun.com/ubuntu/ xenial-updates universe
deb-src http://mirrors.aliyun.com/ubuntu/ xenial-updates universe
deb http://mirrors.aliyun.com/ubuntu/ xenial-security main
deb-src http://mirrors.aliyun.com/ubuntu/ xenial-security main
deb http://mirrors.aliyun.com/ubuntu/ xenial-security universe
deb-src http://mirrors.aliyun.com/ubuntu/ xenial-security universe
3.下载libfuzz-workshop
从https://github.com/c0de8ug/libfuzzer-workshop.git 下载压缩文件,解压缩,使用命令./checkout_build_install_llvm.sh,编译安装llvm和clang。
第一课-介绍fuzz测试
Fuzz是什么
Fuzzing是一种软件测试技术,通常自动或者半自动,通过传递随机输入到程序中,保存程序崩溃的结果。
单元测试和Fuzz的比较
| 单元测试 | 传统Fuzzing | 现代uzzing | |
|---|---|---|---|
| 测试小部分代码 | √ | × | √ |
| 可以自动化 | √ | √ | √ |
| 回归测试 | √ | √ / × | √ |
| 易写 | √ | × | √ |
| 寻找新的BUG | √ / × | √ | √ |
| 寻找漏洞 | × | √ | √ |
目标-Fuzzer-语料库
在Fuzzing研究中,目标,Fuzzer,语料库是我们需要重点关注的内容。
1.测试目标-接受输入,调用被测试代码。
2.Fuzzer,一个向目标写入随机输入的工具。
3.语料库,一个测试数据集合
Fuzz类型
如下图所示。
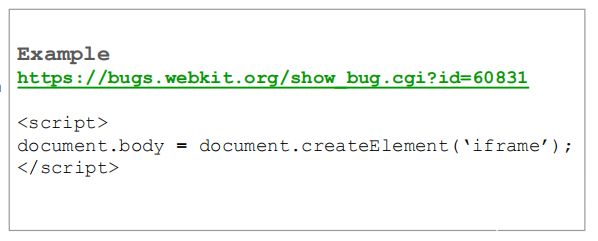
可以看到上图中生成了一个随机id为60831,而该页面会由于给document.body错误赋值导致报错。

上图错误原因为把Iframe类型插入到了document.body,而正确应该插入BODY类型或者FRAMEST类型。或采用下图所示方式给body插入元素。
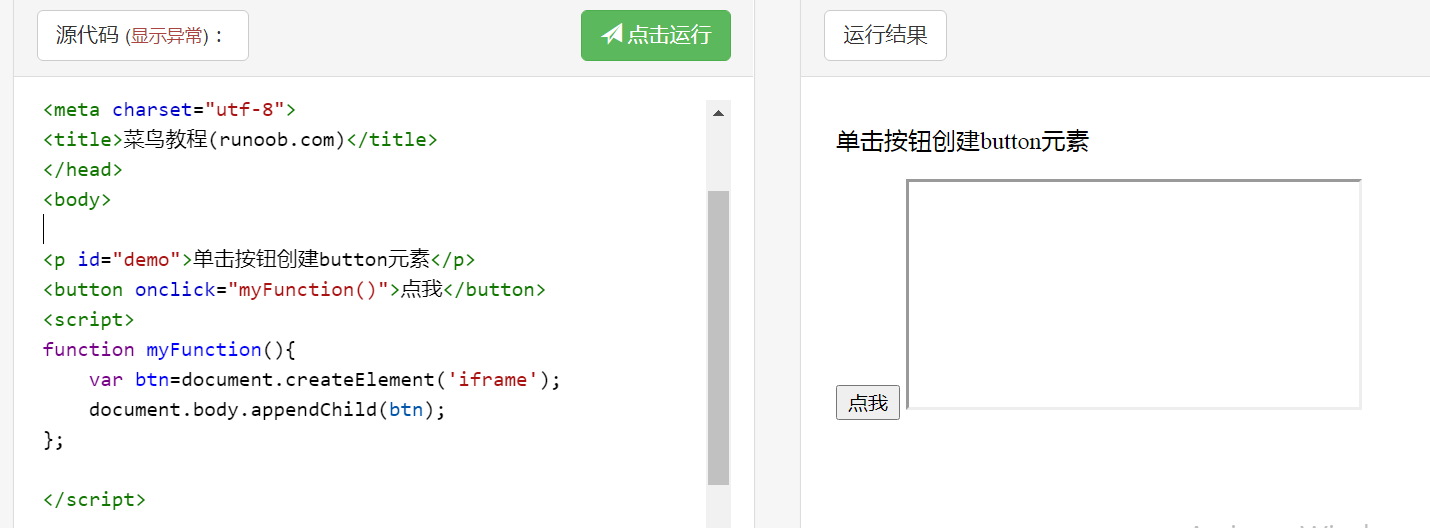
可以看到下图的数据产生方式具有一定规则性,而其他部分则使用变异来完成数据的
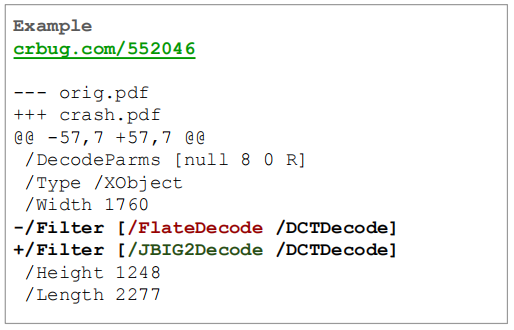
效果更好的策略是什么-结合规则和字典生成与根据代码覆盖率的回馈进行变异
基于规则和变异是很好的方式,但是所有的生成数据样本都有一定的局限性,例如下图的代码:
if(id == "xiaoming"){
//漏洞触发代码
}
如果测试用例中的id的数据样本集合一直在数字这个集合变异,那么肯定测试不到存在漏洞的代码部分,那么更好的策略是什么呢?
将规则和变异共同结合,并且增加代码覆盖率反馈
传统Fuzz技术
在过去的Fuzzing中,我们通常会按照如下流程反复运行,直到找到漏洞:
1.生成一个测试样本,例如html页面
2.写入磁盘
3.打开浏览器
4.输入这个html页面地址
5.查看浏览器是否崩溃
第二课-传统Fuzz技术案例
本节使用 radamsa 作为 变异样本生成引擎,对 pdfium 进行 fuzz。
实战开始
使用如下命令生成测试用例(radamsa根据种子seed_corpus生成)。
cd lessons/02
./generate_testcases.py
#!/usr/bin/env python2
import os
import subprocess
WORK_DIR = 'work'
def checkOutput(s):
if 'Segmentation fault' in s or 'error' in s.lower():
return False
else:
return True
corpus_dir = os.path.join(WORK_DIR, 'corpus')
corpus_filenames = os.listdir(corpus_dir)
for f in corpus_filenames:
testcase_path = os.path.join(corpus_dir, f)
cmd = ['bin/asan/pdfium_test', testcase_path]
process = subprocess.Popen(cmd, stdin=subprocess.PIPE, stdout=subprocess.PIPE,
stderr=subprocess.STDOUT)
output = process.communicate()[0]
if not checkOutput(output):
print testcase_path
print output
print '-' * 80
程序的流程为:
反复调用程序处理刚刚生成的测试用例根据执行的输出结果中 是否有 Segmentation fault 和 error来判断是否触发了漏洞。
使用如下命令验证生成的文件,显示1000则为正确。
ls work/corpus/ | wc -l
通过下列bash反复执行命令,直到发现崩溃即可,该bash已保存为test.sh。
#!/bin/bash
while [ "0" -lt "1" ]
do
rm -rf ./work/
./generate_testcases.py
./run_fuzzing.py
done
如果没有崩溃则反复运行,直到有如下崩溃提示则标志这里存在导致程序崩溃的Bug。
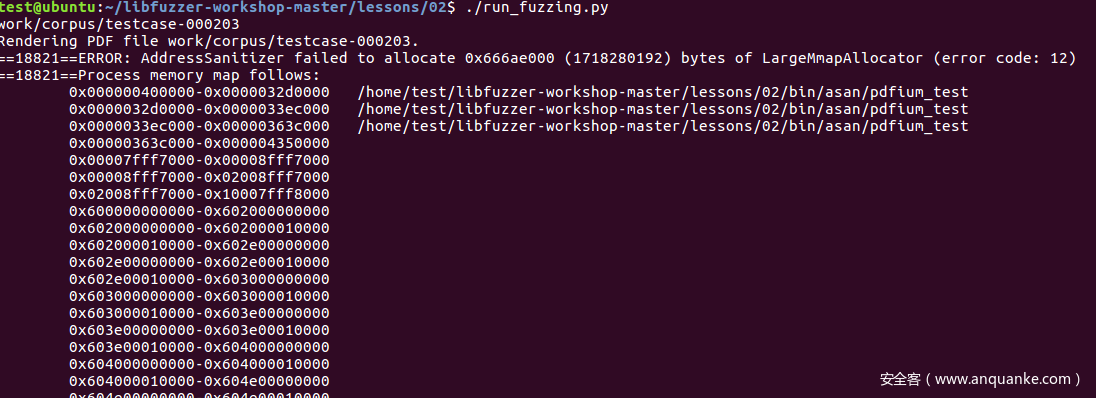
第三课-代码覆盖率fuzzing
传统fuzz技术缺陷
在上述的传统Fuzz方案中,我们可以看到有如下缺陷:
1.样本空间搜索太耗时
2.不能fuzz特定函数
3.很难fuzz网络协议
4.效率很低
更好的Fuzz工具-Libfuzz
鉴于上述问题,引出我们本系列的重点libFuzzer。相比上述的缺点来说。Libfuzzer的优先如下:
1.in-process,coverage-guided,evolutionary 的 fuzz 引擎,是 LLVM 项目的一部分。
2.使用SanitizerCoverage 插桩提供来提供代码覆盖率。
覆盖率指导的模糊测试
下面这些工具可以提供内存错误类型检测。
1.AddressSanitizer(也称为ASan),用来检测UAF,堆栈溢出等漏洞,使用已释放内存, 函数返回局部变量,全局变量越界。
2.MemorySanitizer(也称为MSan),用来检测未初始化内存读漏洞。
3.UndefinedBehaviorSanitizer(也称为UBSan),用来检测整数溢出,类型混淆等。

